1 背景
武林中,“天下武功出少林”指中国各门各派的武功都与少林武学有一定的渊源,技术也是相同的道理,所有的技术最终体现在计算机知识的基本功上,这些基本功是技术的易筋经,是“内功”,一些年轻的攻城狮更热衷于追崇高大上的框架,过去在炒SSH,现在在炒Spring Cloud,这些对框架掌握的程度体现在“剑术”上,我推荐每个技术研发人员在修炼好内功的基础上,再去练“剑术”。回头看IT行业的发展,先有传统行业,再有互联网,传统行业和互联网是少林与武当的关系,他们的技术相辅相成,并不一定是互联网的技术要比传统行业的技术高深很多,而是它们有自己的侧重点,传统行业更偏向于企业级开发,项目具有业务复杂、流程丰富、中心化管理、企业级抽象度高、业务重用率高的特点,而互联网倾向于把复杂的业务进行拆分成单一的职责,对于单一职责模块的非功能质量进行大幅度的优化,这包括高可用性、高性能、可伸缩、可扩展、安全性、稳定性、可维护性、健壮性等。
这篇文章提供一个基本的面向互联网技术评审的方法论,它主要论述在互联网的行业里,如何在完成产品功能的前提下,更好的满足非功能质量的需求,是每个互联网程序设计人员和架构设计人员都应该掌握的一项基本技能。
本文的目的是为了初入互联网或者有意愿踏入互联网的研发人员起到抛砖引玉的效果,如果想全面了解互联网非功能质量设计的方方面面,可以参考美国互联网方法论Architecture Tradeoff Analysis Method。
2 目标
2.1 非功能质量需求的概述
通过参考技术评审指标,保证系统架构设计满足用户和系统对非功能质量的需求:
核心非功能质量:

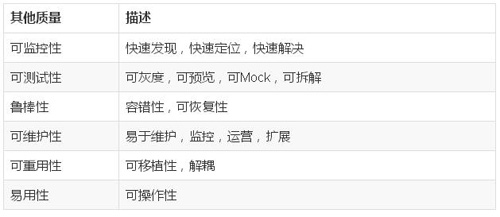
其他非功能质量:
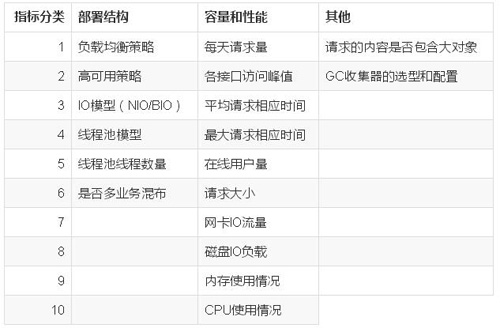
2.2 非功能质量需求的具体指标
主要分为4部分:应用服务器、数据库、缓存和消息队列。
2.2.1 应用服务器
应用服务器是服务的入口,请求流量从这里进入系统,数据库,缓存和消息队列的访问量取决于应用服务器的访问量,对应用服务器的访问量进行评估至关重要,应用服务器主要关心每秒请求的峰值,请求响应时间等指标,通过这些指标可以评估需要的应用服务器资源的数量。
全面考虑下列指标:
2.2.2 数据库
根据应用层的访问量和访问峰值,计算出需要的数据库资源的QPS,TPS,每天的数据总量等,由此来评估所需数据库资源的数量和配置,部署结构等。
全面考虑下列指标:
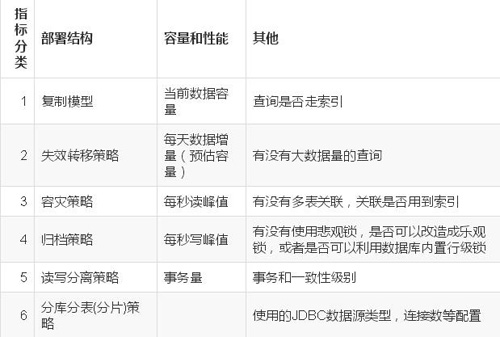
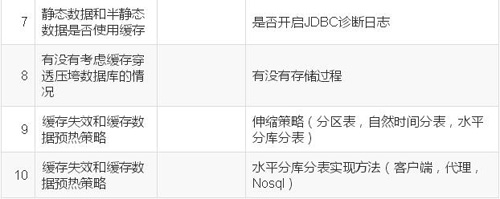
2.2.3 缓存
根据应用层的访问量和访问峰值,通过评估热数据占比,计算出的缓存资源的大小,存取缓存资源的峰值,由此来计算所需缓存资源的数量和配置,部署结构等。
全面考虑下列指标:
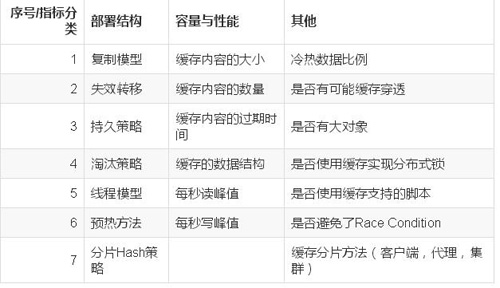
序号/指标分类部署结构容量与性能其他
1复制模型缓存内容的大小冷热数据比例
2失效转移缓存内容的数量是否有可能缓存穿透
3持久策略缓存内容的过期时间是否有大对象
4淘汰策略缓存的数据结构是否使用缓存实现分布式锁
5线程模型每秒读峰值是否使用缓存支持的脚本
6预热方法每秒写峰值是否避免了Race Condition
7分片Hash策略缓存分片方法(客户端,代理,集群)
2.2.4 消息队列
根据应用层的访问量和访问峰值,计算需要消息队列传递的数据内容和数据量,计算出的消息队列资源的数量和配置,部署结构等。
全面考虑下列指标:
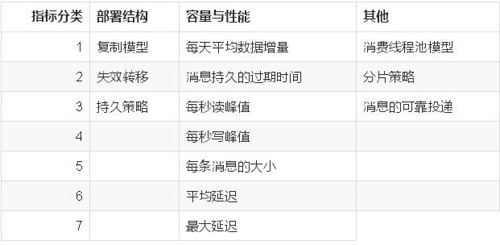
3 技术评审提纲
业务项目千差万别,没有一个统一的方法论完成架构设计和技术评审,架构设计只需要从某些关键点来表达系统即可,提纲就是用来帮助大家做架构评审的工具,帮助大家整理思路并形成可实施的方案,因此在做系统设计时,可有选择性的参考此提纲,根据业务特点来完成一个可实现的有效的架构设计。
3.1 现状
项目名称
- 业务背景
- 业务描述
技术背景
- 架构描述
- 当前系统容量(系统调用量平均值)
- 当前系统调用量峰值
3.2 需求
业务需求
- 要改造的内容
- 要实现的新需求
性能需求
- 预估系统容量(预估系统调用量平均值)
- 预估系统调用量峰值
- 其他非功能质量,例如:安全性、可伸缩等
3.3 方案描述
方案1
- 概述
一句话概括方案的亮点,比如说: 双写,主从分离,分库分表,扩容,归档等。
- 详细说明
方案的具体描述,文字描述不清楚的话可以结合图(任何图:UML,概念图,框图等)的方式说明,如果是改造方案***突出变动的地方,以下列举了几种描述的角度:
中间件架构(应用服务器、数据库、缓存、消息队列等)
逻辑架构(模块划分、模块通信、信息流、时序等)
数据架构(数据结构、数据分布、拆分策略、缓存策略、读写分离策略、查询策略、数据一致性策略)
异常处理,容灾策略,灰度发布
- 性能评估
给出方案的基准数据,并按性能需求评估需要使用的资源数量。
单机并发量
单机容量
按照预估性能需求,预估资源数量(应用服务器、缓存、存储、队列等)
伸缩方式
- 方案优缺点
列出方案的优缺点,优缺点要具有确定性,不要有“存在一定风险”这种描述,也就是要量化。
方案2
整个方案需要参考技术评审指标提出的各方面指标来考虑满足系统的非功能质量需求。
......
3.4 方案对比
对比可选方案,并给出选择这种方案的理由,选择倾向的方案,
3.5 风险评估
标识所选方案的风险,提出解决此风险发生时候的应对策略,比如:上线失败时的回滚策略。
3.6 工作量评估
描述使用所选方案需要做的具体工作,并评估开发、测试等细化任务需要的时间,形成可实施的任务计划表,任务计划表推荐采用简单的表格形式,减少工具使用和学习的成本。
4 性能和容量评估经典案例
4.1 背景
物流系统包含如下两个质量优先需求:
- 维护会员常用地址,下单时提供会员地址列表。
- 下单时异步产生物流订单,物流系统后台任务从第三方物流轮循拉取物流状态,已经下单用户查询订单的物流订单和物流记录。
由于会员数量较大,可能有较快的增长速度,订单数量更是巨大,促销期峰值的订单产生量可能很高,这两个业务模块的数据存储需要分库分表,并借助消息队列和缓存抗写和读的流量,因此,本方案主要涉及这两个业务的容量评估。
4.2 目标数据量级
选取行业内一线电商平台的量级作为目标:
- 会员量2亿,平均增长5万/天。
- 平时订单量400万/天,所有订单下单时段集中在9:00-23:00,促销日订单量1400万/天,50%订单下单时段集中在晚上7:30-8:30和晚上22:00-23:00。
4.3 量级评估标准
通用标准
- 容量按照峰值5倍冗余计算。
- 会员常用地址容量按照30年计算,而物流订单时效性较强按照3年计算。
- 第三方查询接口5000 QPS。
Mysql
- 单端口读:1000 QPS
- 单端口写:700 TPS
- 单表容量:5000万条
Redis
- 单端口读:4万 QPS
- 单端口写:4万 TPS
- 单端口内存容量:32G
Kafka
- 单机读:3万 QPS
- 单机写:5000 TPS
应用服务器
- 请求量每秒峰值:5000 QPS
4.4 方案
方案1. ***性能方案
由于整个电商网站刚刚上线,数据量级还无法清晰的确定,我们根据行业内知名电商当前数据量级设计***性能方案,本方案可以应对行业内电商巨头的各种促销所带来的服务请求峰值,并且拥有最快的响应时间,达到服务性能的***化。
需求1. 会员常用地址
整体流程:
- 提供Restful服务增加会员常用地址。
- 提供Restful服务获取会员常用地址列表。
数据库资源评估:
读QPS:
会员每次下单,拉取一次会员地址列表,按照促销日订单量1400万/天,50%订单下单时段集中在两个小时内计算:
(1400万 × 0.5) / (2 × 60 × 60) = 1000/秒
容量评估按照5倍冗余计算,读QPS峰值1000/秒 * 5 = 5000/秒,需要5端口数据库服务读。
写TPS:
假设每天增加的会员全部添加一次常用地址,并且高峰期会员下订单时有20%的会员会增加一条常用地址:
(1400万 × 0.2 + 5万) / (2 × 60 × 60) = 400/秒
容量评估按照5倍冗余计算,400/秒 * 5 = 2000/秒,需要3端口数据库服务写。
数据容量:
当前有2亿会员,每天增长5万会员,平均每个会员有5个常用地址,30年会员常用地址表数量计算:
(2亿 + 5万 × 365 × 30年) × 5 = 35亿
容量评估按照5倍冗余计算,35亿 * 5 = 175亿,需要350张表即可容纳。
根据以上读QPS、写TPS的评估,如果读写混布我们共需要8端口,可以使用8主8备,如果读写分离,我们需要做主从部署,需要3主6从,与2倍数对齐,使用4主8从即可。
根据表容量,需要350张表,和2的指数对齐,选择512张表,上面计算需要主库端口为4,考虑到将来端口扩展不用拆分数据库,尽量设计更多的库,使用32个库。
设计结果:4端口 × 32库 × 4表, 4主8从
缓存资源评估:
为了提高用户下单的体验,需要使用Redis缓存活跃用户的常用地址。
定义当天下订单的会员为活跃会员,活跃会员的地址缓存24小时,假定每天下订单的会员均为不同会员,每个会员有5个常用地址,缓存大小计算如下:
1400万 × 5 × 1k = 70G
容量评估按照5倍冗余计算,70G×5=350G,按照每台Redis 32G内存计算,需要11台机器,根据数据库对数据存取QPS/TPS的设计,11台机器完全可以满足5000/秒的读QPS和2000/秒的写TPS。
设计结果:11台,主从
应用服务器资源评估:
根据数据库的读QPS(5000/s)峰值和写TPS(2000/s)峰值计算,单台应用服务器即可,选择2台避免单点。
设计结果:2台
需求2. 物流订单和物流记录
整体流程:
- 订单提交后,通过消息队列产生物流订单,消息传入物流系统,物流系统消费物流订单消息然后入库。
- 后台任务轮循未完成物流订单,查询第三方物流接口状态,填写物流记录信息。按照每天1400万的订单,订单平均3天到货,第三方查询接口5000 QPS,每次状态查询需要时间计算如下: 1400万 × 3 / 5000 = 8400 / 60 / 60 = 2小时,定时任务2小时查一次。
- 提供REST服务获取物流订单信息。
- 提供REST服务获取物流记录信息。
- 提供REST服务获取物流订单和物流记录信息。
数据库资源评估:
读QPS:
会员下单三天到货,三天内50%客户会查询一次物流订单和一次物流记录,计算如下:
(1400万 × 3 × 0.5) / (24 × 60 × 60) = 250/秒
容量评估按照5倍冗余计算,2 × 250/秒 × 5倍 = 2500/秒,需要3端口数据库服务读。
写TPS:
会员每次下单,产生一次物流订单,按照促销日订单量1400万/天,50%订单下单时段集中在两个小时内计算:
(1400万 × 0.5) / (2 × 60 × 60) = 1000/秒
按照每天1400万的订单,订单平均3天到货,每条物流订单产生8条物流记录,并且8条物流记录在三天内均匀产生,物流记录写TPS计算如下:
1400万 × 3 × 8 / 3 / (24 × 60 × 60) = 1200/秒
容量评估按照5倍冗余计算,(1000/秒 + 1200/秒) * 5 = 11000/秒,需要15端口数据库服务写。
数据容量:
当前2亿物流订单积累,每天增长400万订单,30年订单数量计算:
2亿 + 400万 × 365天 × 3年 = 46亿
容量评估按照5倍冗余计算,46亿 * 5 = 230亿,需要460张表即可容纳, 物流记录表是物流订单的8倍,460 × 8 = 3680张表。
根据以上读QPS和写TPS,如果读写混布,我们共需要18端口,18主18备,如果读写分离,我们需要16主16从。
根据表容量,需要3680张表,和2的指数对齐,选择4096张表,上面计算需要主库端口为16,考虑到将来端口扩展不用拆分数据库,尽量设计更多的库,使用32个库。
设计结果:16端口 × 32库 × 8表,16主16从
消息队列资源评估:
为了让系统能够应对峰值的突增,采用消息队列Kafka接收物流订单。
根据上面对写TPS的计算,考虑5倍冗余后,峰值为5000/秒,单台Kafka和单台处理机即可处理。
如果峰值有突增,可以增加Kafaka集群的节点来抗写流量,处理机根据后端入库性能来决定。例如写峰值增加10倍,达到5万/秒,需要10台Kafka,每台Kafka读QPS可达3万,理论上需要2台处理机,然而,处理机的瓶颈是后端入库的写TPS,根据上面计算,入库的写TPS峰值按照5000/秒设计,因此,单台处理机即可,这个场景下会有消息的堆积,但是最终会处理完毕,达到消峰的效果。
设计结果:1台Kafka,主从,1台处理机
应用服务器资源评估:
根据数据库的读QPS(2500/s)峰值和写TPS(11000/s)峰值计算,3台应用服务器即可。
用于查询第三方接口的后台任务服务器,由于受到第三方接口5000/s的QPS的限制,单台机器即可,为了避免单点,2台处理机即可。
设计结果:2台
方案2. 最小资源方案
由于当前系统线上数据量并不多,增长量也不大,读QPS和写TPS单台机器完全可以处理,暂时不考虑使用缓存和消息队列,但是保留使用缓存和消息队列的接口,如果缓存和消息队列的资源可用,可以通过开关进行切换。
当前的数据量使用单库单表即可处理,然而,考虑到将来扩容方便,数据库端口暂时使用一个,但是保留我们在***性能方案中对数据库的分库分表,当读QPS和写TPS突增时,DBA可以把库重新拆分到多个端口来抗请求流量。
因此,方案如下:
会员常用地址
设计结果:1端口 × 32库 × 16表, 1主1从
物流订单和物流记录
设计结果:1端口 × 128库 × 32表,1主1从
4.5 总结
倾向于采用最小资源方案:
当前线上流量并不大,使用最小资源方案节省成本。
最小资源方案充分的考虑了数据库的分库分表,当读QPS和写TPS突增时,DBA可以拆分库到不同的端口,也就是增加端口来应对。
最小资源方案在应用层设计了开关,如果性能突增可以临时申请和开启缓存和消息队列。
5 性能评估参考标准
以下标准是使用PC X86机器的经验值,仅供参考,评审时应该随着机器的不同而做调整。
通用标准
- 容量按照峰值5倍冗余计算。
- 分库分表后的容量一般可存储30年的数据。
- 第三方查询接口5000 QPS。
- 单条数据库记录占用大约1K空间。
Mysql
单端口读:1000 QPS
单端口写:700 TPS
单表容量:5000万条
Redis
单端口读:4万 QPS
单端口写:4万 TPS
单端口内存容量:32G
Kafka
单机读:3万 QPS
单机写:5000 TPS
DB2
单机读峰值:20000
单机写峰值:20000
单表容量:1亿数据
6 总结
本文以互联网企业重点关注的非功能质量为主线,总结了非功能质量需求的总体目标,并针对不同的服务和资源列举了不同的非功能质量需求,帮助读者在做技术评审的过程整理思路,尽量穷举评审时关注的评审点,并随后提供了一个简单有效的评审提纲,***根据提纲实现一个互联网容量和性能评估的经典案例,大家可以在案例中了解高并发互联网系统是如何进行拆分的,以及依据哪些数据进行拆分。
由于本文的数据完全是基于笔者在某个互联网平台下的经验而记录的,并不代表可以直接应用在任何企业和平台上,这里重点突出进行容量和性能评估的方法论,帮助大家整理实现高并发互联网系统的思路。
根据本文的容量评估,我们需要分布式的中间件支持对数据库、缓存和消息队列的水平伸缩和分片。
点击《互联网性能与容量评估的方法论和典型案例》阅读原文。
【本文为51CTO专栏作者“李艳鹏”的原创稿件,转载可通过作者简书号(李艳鹏)或51CTO专栏获取联系】